使ってみたという話をします。
その前に、プレスリリースのタイトルがとても気になる。
「要件定義システム生成AI」
明らかに「要件定義システム」を生成するAIではないので、要件定義 (及び) ・システム生成AIとすべきでしょう!
とまずは文句を打ち込みつつ、どんなシステムを作ってもらうかを考えた。
開発エディタに行けば分かるが、使い方は自然言語でシステムの要旨を入力すると、要件を精密化した上でそれに則したシステム (コード) を生成するようになっている。
生成まで
方針(入力)は以下のようにした。
# Input
Amazon DynamoDB上にある25000件の商品データを検索するシステム。
当該データを格納するテーブル product は3つの属性 (attribute) を持っており、それぞれ
* product_name: TEXT
* product_type: TEXT(32桁)
* product_price: INT
となっている。これら3属性は全て検索対象項目である。
pythonの何らかのWebフレームワークを使用して、Amazonのコンテナ上にAPIとして展開したい。
上記のAPIサーバとは別に、インターフェイス (検索画面) 様のEC2インスタンスを立ち上げ、UI/UXをNext.jsで構築する。
product_nameは部分文字列で検索。product_typeは入力するごとに入力文字列をprefixとする候補が絞られていく形式。product_priceは上限と下限の範囲指定である。
入力・生成が終わると、システムフレームワークを選択できるので、 backend_fastapi を選択した。
約10秒程すると、一連のファイルがダウンロードできるようになった。
ダウンロードしたZIPファイルのTOPディレクトリに requirements.txt というファイルがある。これが要件書のようである。
# /requirements.txt
以下に、要求に基づいた簡潔な機能要件を記述します:
"""
- Amazon DynamoDB上の25000件の商品データを検索するAPIサーバをPythonのWebフレームワークを使用してEC2コンテナ上に構築
- 検索対象は product_name(部分文字列)、product_type(プレフィックス検索)、product_price(範囲指定)の3属性
- 別のEC2インスタンス上にNext.jsを用いたUI/UXを構築し、直感的な検索インターフェースを提供
- product_typeの入力補完機能の実装
- 高速かつ効率的な検索処理の実現と、ユーザーフレンドリーな検索体験の提供
"""情報としては余り増えてないが、入力が詳細だったので補完するところが少なかったのだと思う。
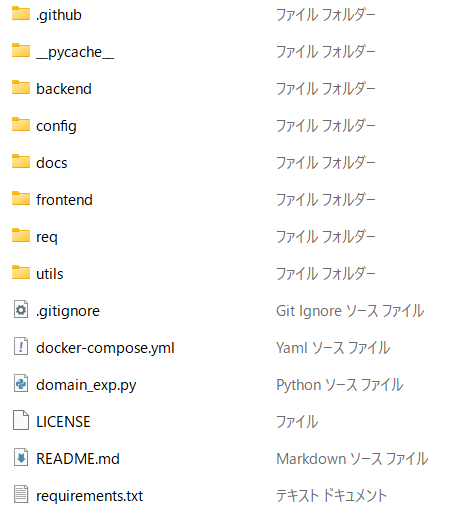
構成は次のようである。
評価
sqliteへのconnector設定が生成されていたり(/backend/app/core/config.py)、DynamoDBと指定したのにPostgreSQLが docker-compose.yml内に生成されるなど、構成に不可解な点はままある (DynamoDBのconnector自体は生成されている – /backend/app/core/database.py )。
試しに生成されたままのソースからMockを動かしてみようと適当な環境で構築を試みたものの、結果的に /frontend のdocker buildで失敗した (次の箇所)。
# 依存関係をインストール
RUN npm ciこの問題を解決する時間が無かったのでそれっきりだが、Babel由来だという確証は持っていない。少なくともnpmの依存関係解消にはかつて私もハマった記憶があるので、比較的同情的である。
良い点を挙げると、個別のアプリケーション・モデル(フレームワーク)に則したソースコードとしては、標準的で、そこそこ使える質のものができている。 /backend と /frontend 以下のソースコードを、snippetとして参照しながら使うのは便利だと思う。
総評
総評は2段構えで書く。[1] … Continue reading
- プレスリリースで書いてある性能が誇張ではないかどうか
- 要件定義の実務で使えるかどうか
1. プレスリリースで書いてある性能が誇張ではないかどうか
| 告知項目名 | 告知項目説明 | 評価(〇△×) | 評価説明 |
|---|---|---|---|
| 要件定義プログラミング | 自然言語による要件記述から直接実行可能なコードを生成 | × | そのままでは実行可能ではない。 |
| 自動要件定義生成 | 顧客の要望やビジョンを入力するだけで、Babelが詳細な要件定義を自動的に作成 | 〇 | これは言語モデルが良くなってるお陰か、まぁまぁ凄い。 |
| 自律的システム構築 | 生成された要件定義に基づき、Babelが独自にシステムの設計、開発 | 〇 | 嘘ではない。 |
| グラフ型空間コンピューティングによる視覚的な開発体験 | 2D、3D空間内でシステム構造を可視化し、直感的な操作が可能 | 〇 | 嘘ではない。 「開発体験」というレベルには行ってない気がするが、展望の話だろうか。 |
| 並列実行マルチAIエージェント | 複数のAIエージェントが並列で作業を行い、効率的にシステムを構築 | – | 操作してるだけでは実態は分からないので未評価。 |
| 高い柔軟性と拡張性 | 様々な業界や規模の企業に対応可能 | 〇 | 3つ試したが、ドメインが違ってもある程度対応できそう。 |
| 開発期間の大幅短縮 | 一人月規模の開発、150ファイル近くの生成を2,3分で完了 | △ | 嘘ではないかも知れないが、誇張。生成できるファイル数で比較してみたところで、「一人月規模の人的リソースを代替できる」と主張するのはどうなのか。 |
2. 要件定義の実務で使えるかどうか
2.1. 要件書
プロジェクトを説明する要件のアブストラクトの下書きとして使えると思う。
ただGTP等別の汎用LLMでも近しい事は出来るかも知れない。
2.2. アーキテクチャ
使えなさそう。
アプリケーション・アーキテクチャは生成される成果物に内包される形で、ある程度Fixされている戦略を取っているので、各レイヤーごとのアーキテクチャ (Service, Network, Data, …) と呼べる程の資料は出てこない。
ただこれは恐らくBabelのスコープ外。
2.3. セットアップ(IaC)
コンテナ(IaC)周りの生成物にまだ微妙に手直しが必要そうなので、その意味では使えない。
要件定義の文脈では、企画・構想が終わって要件が固まった段階で、素早くビジネスロジックから直通で生成して動くものを検証できるかが重要。
2.4. セットアップ (CI/CD)
下書きで使える。
標準的な設定が生成されていた。
2.5. アプリケーションコード
モックコードの下書きとして使える。
勝手に展望
現時点では、ミドルウェア(Server Application)、フロントエンド (Next.js)、バックエンド (Python, FastAPI) ごとに生成されたシステムリソースの連動を調整するのに手直しがそこそこ必要そうなので、ビジネスロジックをモックに変換して試しながら考えよう、とまでは至らない。
しかしこれはプレスリリースしたばかりで今後すぐに改善されていくだろうし、リリースページに表示されてる機能全てを使えている訳でもどうやらなさそうなので、とても期待している。
個人的にはもう少しユーザに専門性を求めても良いから、ドメイン駆動開発とAI駆動開発の合わせ技のプロダクトがいずれ発展形として現れると、クライアントにも提案しやすい。
Footnotes
| ↑1 | 最初のInputだけではInputが悪い可能性があったので、もう二回バリエーションを変えて生成してみた。
結果、総評としては変わらなかったが、簡易で直観的な説明「Xから~という条件で定時クローリングしてくるバッチシステム」の方が、補完した要件書と付随して生成される成果物の恩恵が分かりやすい。 |
|---|